1. 编码问题
i.请说明python2与python3中的默认编码是什么?
python2 ASCII 码 python3 字符串为unicode,文件默认编码为utf-8
ii.为什么会出现中文乱码?你能列举出现乱码的情况有哪几种?
读取使用的编码和存储时使用的编码不一致造成的。
存储的时候是GBK,打开的时候是使用UTF-8编码,就会出现乱码
iii.如何进行编码转换?
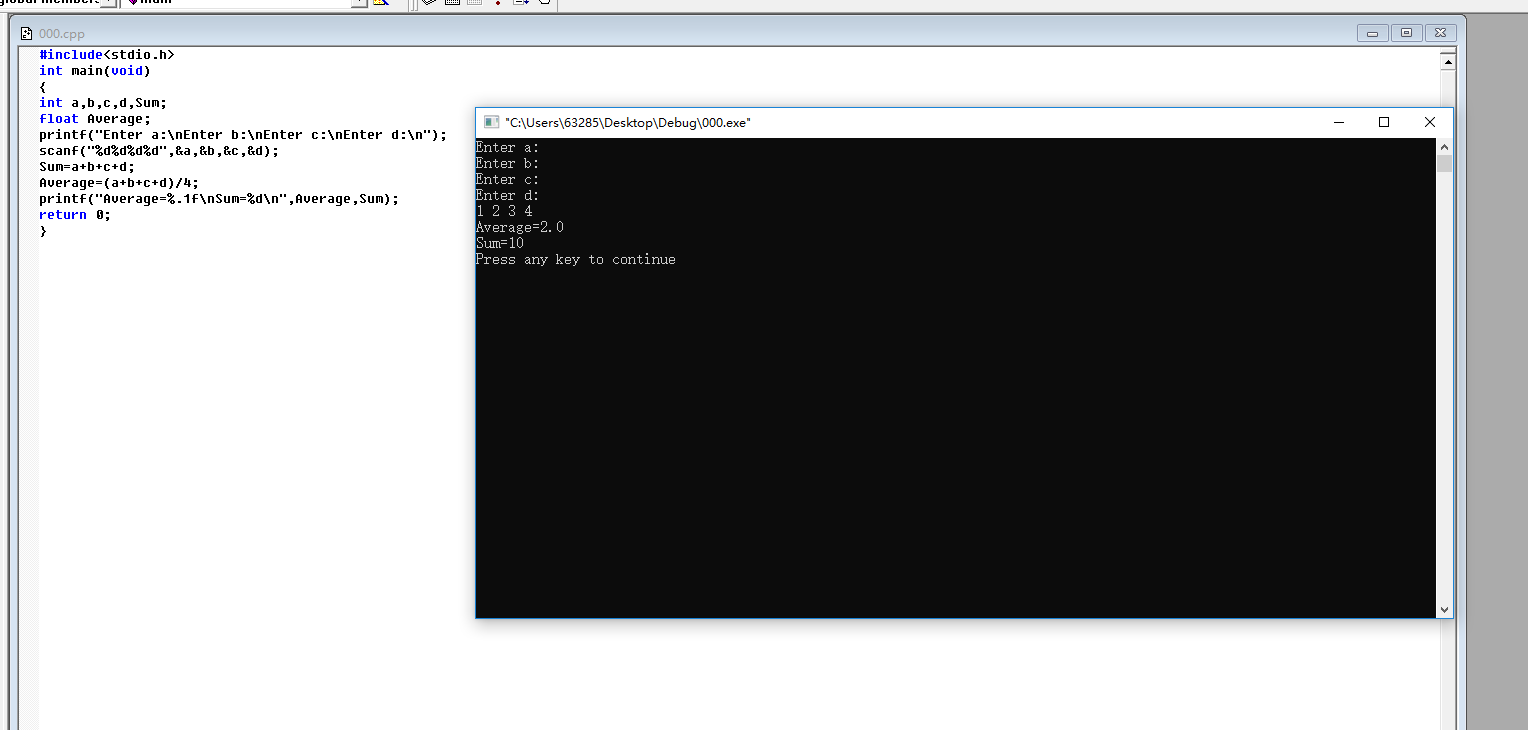
h = "你好" print(h) print(type(h)) h1 = h.encode(encoding="utf-8") #将字符串编码成utf-8的bytes print(h1) print(type(h1)) h2 = h1.decode(encoding="utf-8").encode(encoding="gbk") print(h2) print(type(h2)) h3 = h2.decode(encoding="gbk") #将gbk编码的bytes解码成字符串(unicode) print(h3) print(type(h3)) 你好 <class 'str'> b'\xe4\xbd\xa0\xe5\xa5\xbd' <class 'bytes'> b'\xc4\xe3\xba\xc3' <class 'bytes'> 你好 <class 'str'>
iv. #-*-coding:utf-8-*- 的作用是什么?
使用utf-8编码。
v. 解释py2 bytes vs py3 bytes的区别:
py2的 bytes和str 是一样的
py3的bytes就是二进制字节
2. 文件处理
i. r 和 rb 的区别是什么?
r 以只读的模式打开文件
rb 以只读的二进制模式打开文件
ii. 解释一下以下三个参数的分别作用
open(f_name,'r',encoding="utf-8")
f_name 是文件名,r 为读的模式, encoding="utf-8" 为打开文件编码
函数基础:
1. 写函数,计算传入数字参数的和。(动态传参)
def num_sum(*args):
total_sum = 0
for i in args:
total_sum += i
print(total_sum)
num_sum(2,3,4,-1,12)
2. 写函数,用户传入修改的文件名,与要修改的内容,执行函数,完成整个文件的批量修改操作
import os
def updata(file,old_contents,new_contents):
with open(file,"r",encoding="utf-8") as f ,open("tmp","w",encoding="utf-8") as f1:
for line in f:
line = line.replace(old_contents,new_contents)
f1.write(line)
os.remove(file)
os.rename("tmp",file)
updata("file.txt","hello","hi")
3. 写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空内容。
def isnull(arg):
for i in arg:
if str(i).isspace():
print("有空白字符,空格 或 制表符 或 换行")
isnull(("hh","gg"," ","dd"))
4. 写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
def my_dic(*args,**kwargs):
for i in kwargs:
if len(kwargs[i]) > 2:
print(len(kwargs[i]))
kwargs[i] = kwargs[i][:2]
return kwargs
dic = {"k1": "v1v1", "k2": [11,22,33,44]}
print(my_dic(**dic))
5. 解释闭包的概念。
在一些语言中,在函数中可以(嵌套)定义另一个函数时,如果内部的函数引用了外部的函数的变量,则可能产生闭包,就是当某个函数被当成对象返回时,夹带了外部变量,就形成了一个闭包。
函数进阶:
1. 写函数,返回一个扑克牌列表,里面有52项,每一项是一个元组 例如:[(‘红心’,2),(‘草花’,2), …(‘黑桃A’)]
def poker():
type_list = ("黑桃","红桃","方块","梅花")
num_list = (1,2,3,4,5,6,7,8,9,10,"J","Q","K")
poker_list = []
for i in type_list:
for j in num_list:
poker_list.append((i,j))
print(poker_list)
poker()
2. 写函数,传入n个数,返回字典{‘max’:最大值,’min’:最小值}
例如:min_max(2,5,7,8,4)
返回:{‘max’:8,’min’:2}
def min_max(*args):
max = args[0]
min = args[0]
for i in args:
if i >max:
max = i
if i< min:
min = i
return {"max":max, "min":min}
print(min_max(100,-6,2,3,6,98))
3. 写函数,专门计算图形的面积
其中嵌套函数,计算圆的面积,正方形的面积和长方形的面积
调用函数area(‘圆形’,圆半径) 返回圆的面积
调用函数area(‘正方形’,边长) 返回正方形的面积
调用函数area(‘长方形’,长,宽) 返回长方形的面积
def area():
def 计算长方形面积():
pass
def 计算正方形面积():
pass
def 计算圆形面积():
pass
def area(shape,*args): def rectangular(*args): area_total = args[0]*args[1] print(area_total) def square(*args): area_total = args[0] * args[0] print(area_total) def circular(*args): area_total = 3.14* args[0] * args[0] print(area_total) if shape == "长方形": return rectangular(*args) elif shape == "正方形": return square(*args) elif shape == "圆形": return circular(*args) area("圆形",2)
4. 写函数,传入一个参数n,返回n的阶乘 例如:cal(7) 计算7*6*5*4*3*2*1
def cal(n):
total = 1
for i in range(1,n+1):
total *= i
print(total)
cal(7)
5. 编写装饰器,为多个函数加上认证的功能(用户的账号密码来源于文件),要求登录成功一次,后续的函数都无需再输入用户名和密码
import json
logged = False
global_user = ""
def auth(fun):
def inner(*args,**kwargs):
global logged
if logged == False:
user = {
"zhangsan": ["zhangsan666",3,False],
"lisi": ["lisi666",0,True],
"wangwu": ["wangwu666",0,True]
} #用户名:[密码,密码输错次数,False锁定用户]
while True:
name = input("请输入你的姓名:").strip()
try:
with open("lockedname.txt","r+",encoding="utf-8") as f:
user = json.load(f) #若是有lockedname.txt文件,则user重新赋值
with open("expenses_record.txt", "r+", encoding="utf-8") as f2:
record_info = json.load(f2) # 若是有lockedname.txt文件,则user重新赋值
except Exception as err:
pass
if name not in user:
print("用户名不存在,请重新输入")
continue
elif user[name][2] == False:
print("用户已经被锁定,请联系管理员")
continue
elif record_info[name]["frozen"] == True:
print("账号已经被冻结,请联系管理员")
continue
elif name in user:
passwd = input("请输入你的密码:").strip()
if passwd == user[name][0]: # 判断用户名密码
print("欢迎 %s 同学"%(name))
user[name][1] = 0
with open("lockedname.txt", "w", encoding="utf-8") as f:
json.dump(user, f)
logged = True
global global_user
global_user = name
result = fun(*args,**kwargs)
return (0, name)
else:
user[name][1] += 1 # 同一个用户名输错密码加一
print("密码错误")
if user[name][1] >= 3:
print("用户账号已被锁定")
user[name][2] = False
with open("lockedname.txt", "w", encoding="utf-8") as f:
json.dump(user, f)
else:
result = fun(*args, **kwargs)
return inner
@auth
def tixian(name, cash_amount):
pass
@auth
def zhuanzhuang():
pass
生成器和迭代器
1. 生成器和迭代器的区别?
生成器是迭代器的一种,能做所有迭代器的事,而且因为自动创建了 iter()和 next()方法,生成器简洁,高效。使用生成器节省内存。
2. 生成器有几种方式获取value?
next()
for 循环
3. 通过生成器写一个日志调用方法,支持以下功能
根据指令向屏幕输出日志
根据指令向文件输出日志
根据指令同时向文件&屏幕输出日志
日志格式如下
2017-10-19 22:07:38 [1] test log db backup 3
2017-10-19 22:07:40 [2] user alex login success
代码结构如下
def logger(filename,channel='file'):
"""
日志方法
:param filename: log filename
:param channel: 输出目的地,屏幕(҅terminal),文件(file),屏幕+文件(both)
:return:
"""
...your code...
#调用
log_obj = logger(filename="web.log",channel='both')
log_obj.__next__()
log_obj.send('user alex login success')
import logging
def logger(filename,channel='terminal'):
"""
日志方法
:param filename: log filename
:param channel: 输出目的地,屏幕(҅terminal),文件(file),屏幕+文件(both)
:return:
"""
log = logging.getLogger()
log.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
fh = logging.FileHandler(filename, encoding="utf-8")
fh.setLevel(logging.DEBUG)
formatter = logging.Formatter(
fmt="%(asctime)s %(message)s",
datefmt="%Y/%m/%d %X",
)
ch.setFormatter(formatter)
fh.setFormatter(formatter)
count = 0
while True:
count += 1
mg = yield "ok"+str(count)
# mg = yield
meg = "[%s] %s"%(count,mg)
if channel == 'terminal':
log.addHandler(ch)
log.info(meg)
log.removeHandler(ch)
elif channel == 'file':
log.addHandler(fh)
log.info(meg)
log.removeHandler(fh)
elif channel == 'both':
log.addHandler(ch)
log.addHandler(fh)
log.info(meg)
log.removeHandler(ch)
log.removeHandler(fh)
ll = logger("text.log",channel='both')
print(ll.__next__())
print(ll.send('user alex login success'))
ll.send('user lili login success')
ll.send('user nana login success')
内置函数
1,用map来处理字符串列表,把列表中所有人都变成sb,比方alex_sb
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
def f(arg):
arg = arg+"_sh"
return arg
lis = ["alex","lili","wangwu"]
lis_new = map(f,lis)
print(lis_new.__next__())
print(lis_new.__next__())
print(lis_new.__next__())
2,用filter函数处理数字列表,将列表中所有的偶数筛选出来
filter()用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
num
=
[
1
,
3
,
5
,
6
,
7
,
8
]
def f1(n):
if n%2 == 0:
return True
else:
return False
num = [1,3,5,6,7,8]
num_new = filter(f1,num)
print(num_new.__next__())
print(num_new.__next__())
num_new2 = filter(lambda x:x%2 == 0,[1,3,5,6,7,8])
print(num_new2.__next__())
print(num_new2.__next__())
3,如下,每个小字典的name对应股票名字,shares对应多少股,price对应股票的价格
portfolio
=
[
{
'name'
:
'IBM'
,
'shares'
:
100
,
'price'
:
91.1
},
{
'name'
:
'AAPL'
,
'shares'
:
50
,
'price'
:
543.22
},
{
'name'
:
'FB'
,
'shares'
:
200
,
'price'
:
21.09
},
{
'name'
:
'HPQ'
,
'shares'
:
35
,
'price'
:
31.75
},
{
'name'
:
'YHOO'
,
'shares'
:
45
,
'price'
:
16.35
},
{
'name'
:
'ACME'
,
'shares'
:
75
,
'price'
:
115.65
}
]
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
def f2(i):
if i['price'] > 100:
return True
portfolio_new = filter(f2,portfolio)
# print(portfolio_new.__next__())
# print(portfolio_new.__next__())
for i in portfolio_new:
print(i)